
Beyond performance: robustness-oriented model evaluation
카테고리: AI in Medicine
태그: ablation study model evaluation robustness sensitivity analysis AI in Medicine
단일 모델의 최고 성능을 보고하는 것을 넘어, 분석 조건 변화에 대한 결과의 안정성(sensitivity analysis)과 모델 구성요소의 실제 기여도(ablation study)를 함께 검토하는 접근은 강건성 중심의 모델 평가라고 할 수 있다. 처음 ML/DL approach를 자신의 보건의료 문제 해결에 적용하려고 하거나, 학생들이 가장 빠지기 쉬운 함정이야말로 (데이터도 활용처도 불분명한) 성능에 대한 집착(!)일 것이다.
그러나 좋은 모델이란 단순히 AUROC, accuracy, F1-score가 높은 모델만을 의미하지 않는다. 연구자가 선택한 코호트 정의, outcome 정의, 결측 처리 방식, cutoff, train-test split, random seed, 또는 모델 아키텍처의 특정 구성요소에 따라 결과가 크게 달라진다면, 그 모델의 결론은 충분히 신뢰하기 어렵다.
이 지점에서 sensitivity analysis와 ablation study가 중요해진다. Sensitivity analysis는 분석 조건이나 조작적 정의를 바꾸어도 연구 결론이 유지되는지를 확인하는 강건성 검토이다. 반면 ablation study는 딥러닝 모델의 특정 구성요소를 제거하거나 변형함으로써 각 요소가 실제 성능 향상에 기여했는지를 평가하는 구성요소 기여도 분석이다.
두 방법은 서로 다른 연구 전통에서 발전했지만, 공통적으로 모델과 분석 결과의 신뢰성을 평가한다는 점에서 같은 철학을 공유한다. 둘 다 “모델이 얼마나 좋은가?”라는 질문을 넘어 “그 결과를 왜 믿을 수 있는가?” 라는 질문에 답한다. 이는 성능 중심 모델 개발을 넘어선 강건성 기반 모델 평가라는 맥락에서 이해할 수 있다. 오늘은 이 두 가지에 대해 살펴보고자 한다.
1. Sensitivity analysis: 분석 선택에 대한 결과의 강건성
통계학, 임상역학, 보건의료 빅데이터 연구에서 sensitivity analysis는 분석 결과가 특정 가정이나 조작적 정의에 얼마나 의존하는지를 평가하는 방법이다. 예를 들어 건강보험 청구자료를 이용한 연구에서는 질병 발생을 어떻게 정의하는지가 매우 중요하다. 특정 상병코드 1회 이상을 outcome으로 볼 것인지, 주상병 기준으로 제한할 것인지, 2회 이상 반복 청구를 요구할 것인지, 관련 약물 처방을 함께 요구할 것인지에 따라 결과가 달라질 수 있다.
예를 들어 어떤 만성질환(가령 천식)의 발생을 평가하려는 연구에서 해당 질환의 진단코드를 그대로 신뢰하기 어렵거나 직접 사용할 수 없다고 하자. 이 경우 연구자는 관련 약물 처방, 전문 진료과 방문, 관련 진단군 등을 조합한 대체 조작적 정의를 고민할 수 있다. 그러나 이때 중요한 것은 하나의 정의만 선택해 결과를 제시하는 것이 아니다. 가능한 여러 정의를 적용했을 때도 결론의 방향과 크기가 유지되는지를 확인해야 한다. 이것이 sensitivity analysis의 핵심이다.
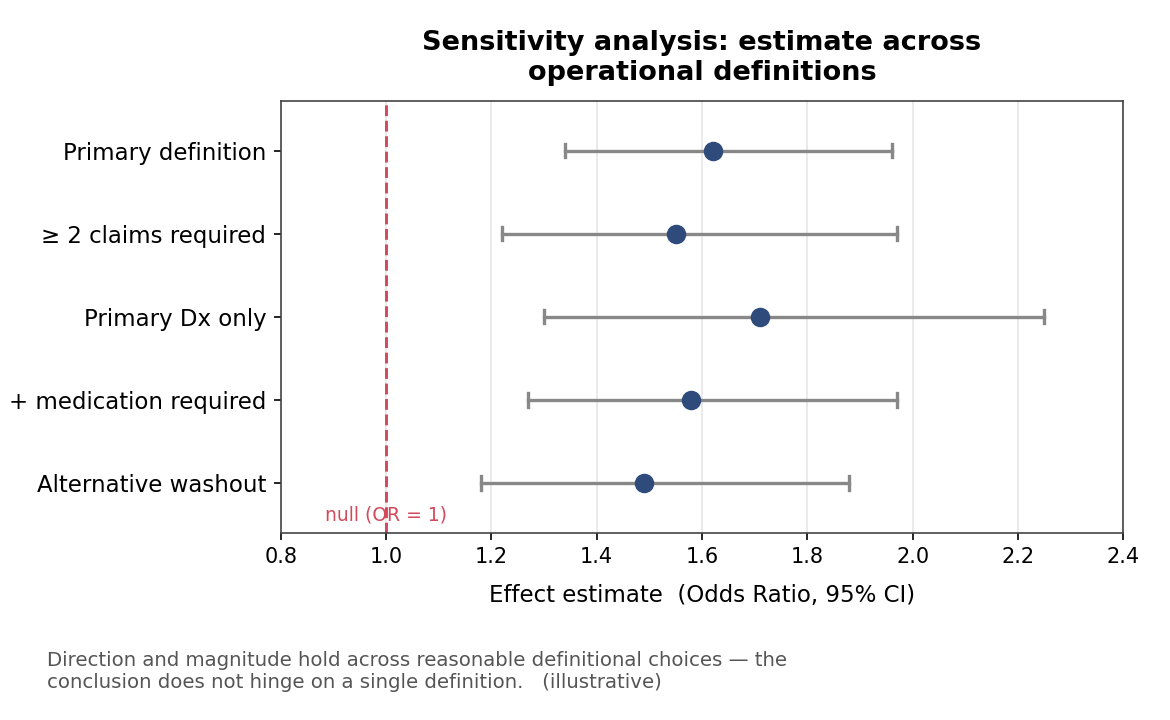 Figure 1. 여러 조작적 정의를 적용해도 효과 추정치의 방향과 크기가 유지된다면, 결론은 특정 정의 하나에 의존하지 않는다고 볼 수 있다. (개념적 예시)
Figure 1. 여러 조작적 정의를 적용해도 효과 추정치의 방향과 크기가 유지된다면, 결론은 특정 정의 하나에 의존하지 않는다고 볼 수 있다. (개념적 예시)
즉, sensitivity analysis는 다음과 같은 질문을 던진다.
“연구자가 분석 과정에서 합리적으로 선택할 수 있는 다른 길을 택했더라도, 결론은 여전히 유지되는가?”
2. Ablation study: 모델 구성요소의 실제 기여도
반면 딥러닝에서 ablation study는 모델 내부 구성요소의 기여도를 평가하는 실험이다. 새로운 모델 구조를 제안했을 때 단순히 전체 모델의 성능이 좋다고 말하는 것만으로는 충분하지 않다. 모델 안에 포함된 attention layer, positional encoding, dropout, class weighting, feature embedding, data augmentation, residual connection 등이 실제로 성능 향상에 기여했는지를 보여주어야 한다.
예를 들어 Transformer 기반 텍스트 분류 모델을 개발했다고 하자. 전체 모델은 embedding layer, positional encoding, multi-head attention, feed-forward network, dropout, layer normalization, classification head로 구성되어 있다. 이때 ablation study는 다음과 같은 방식으로 설계할 수 있다.
- positional encoding을 제거했을 때 성능이 얼마나 감소하는가?
- dropout을 제거하면 overfitting이 증가하는가?
- class weight를 제거하면 minority class의 F1-score가 떨어지는가?
- multi-head attention 대신 단순 pooling을 사용하면 성능이 유지되는가?
- sequence length를 줄이거나 늘렸을 때 결과가 달라지는가?
이러한 실험은 단순히 “모델이 좋다”는 주장을 넘어 “모델의 어떤 요소가 왜 필요한가”를 설명한다. 예를 들어 전체 모델의 macro-F1이 0.86인데 class weight를 제거했을 때 macro-F1은 0.84로 조금만 감소하고 minority class F1은 0.61에서 0.42로 크게 감소했다고 하자. 이 경우 class weight는 전체 정확도를 크게 높이는 요소라기보다, 불균형 데이터에서 소수 클래스를 보호하는 장치로 해석할 수 있다. 이런 해석은 단일 성능지표만으로는 드러나지 않는다.
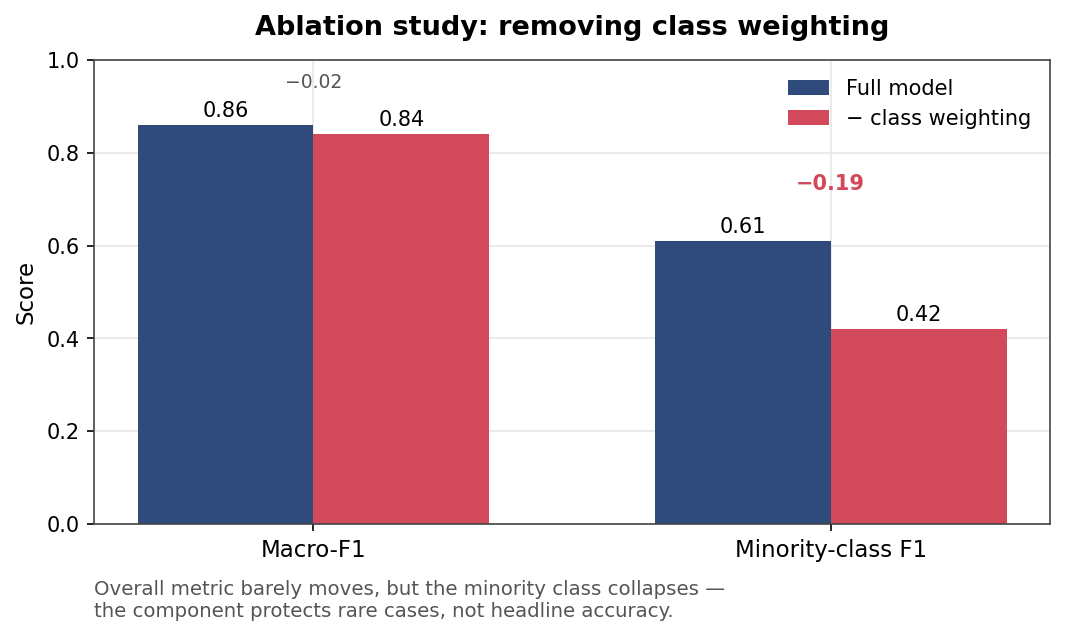 Figure 2. class weight를 제거하면 전체 지표(macro-F1)는 거의 변하지 않지만 소수 클래스의 F1은 크게 무너진다. 즉 이 구성요소는 headline accuracy가 아니라 희소 사례를 보호하는 역할을 한다. (본문 예시 수치)
Figure 2. class weight를 제거하면 전체 지표(macro-F1)는 거의 변하지 않지만 소수 클래스의 F1은 크게 무너진다. 즉 이 구성요소는 headline accuracy가 아니라 희소 사례를 보호하는 역할을 한다. (본문 예시 수치)
Ablation study는 특히 딥러닝 연구에서 중요하다. 딥러닝 모델은 구성요소가 많고, 성능 향상의 원인이 명확하지 않은 경우가 많다. 복잡한 모델이 좋은 성능을 냈다고 해서 그 복잡성이 반드시 필요한 것은 아니다. 때로는 단순한 baseline 모델이 거의 같은 성능을 낼 수도 있고, 제안한 핵심 모듈이 실제로는 성능에 거의 기여하지 않을 수도 있다. Ablation study는 이러한 가능성을 검증하는 방법이다.
즉, ablation study는 다음과 같은 질문을 던진다.
“이 모델의 성능 향상은 정말 제안한 구성요소 때문인가?”
3. 성능지표만으로는 부족한 이유
모델 개발 연구에서 가장 흔한 오류는 최고 성능 하나에 과도하게 집중하는 것이다. 예를 들어 여러 모델을 비교한 뒤 XGBoost의 AUROC가 0.91이고 Random Forest의 AUROC가 0.89였다는 이유만으로 XGBoost가 더 우수하다고 결론 내리는 경우가 있다. 그러나 두 모델의 성능 차이가 데이터 분할 방식, random seed, class imbalance 처리, threshold 선택, 또는 평가 구간 정의에 따라 쉽게 바뀐다면, 그 결론은 안정적이지 않다.
평가 범위를 잘못 설정할 때도 비슷한 문제가 발생한다. 예를 들어 전체 환자를 대상으로 어떤 질환을 선별(screening)하는 모델을 평가한다고 하자. 그러나 임상적으로 중요한 질문이 “고위험군에서의 검출 성능”이라면, precision·recall과 같은 지표를 계산하는 분모(denominator) 역시 그 고위험군에 맞추어 정의하고 해석해야 한다. 만약 대다수가 저위험군인 전체 집단을 분모로 사용하면, 쉽게 분류되는 다수의 음성 사례가 지표를 끌어올려 정작 중요한 고위험군에서의 성능이 희석되거나 왜곡될 수 있다. 이 경우 문제는 단순히 코드 구현의 오류가 아니라 평가 설계의 문제다.
따라서 모델 평가에서는 다음을 구분해야 한다.
- 모델이 전체 데이터에서 평균적으로 좋은 성능을 보이는가.
- 임상적 또는 연구적으로 중요한 하위 구간에서도 좋은 성능을 보이는가.
- 분석 조건을 바꾸어도 성능과 결론이 유지되는가.
- 모델의 각 구성요소가 실제로 필요한가.
이 네 가지 질문에 답하지 않고 단일 성능지표만 제시하는 연구는 설득력이 제한적일 수밖에 없다.
4. Robustness-oriented model evaluation이라는 관점
Sensitivity analysis와 ablation study는 서로 다른 방법이지만, 더 넓게 보면 둘 다 robustness-oriented model evaluation, 즉 강건성 기반 모델 평가의 일부로 볼 수 있다.
Sensitivity analysis는 주로 데이터 정의, 분석 가정, 조작적 정의, 통계적 처리 방식의 변화에 대한 강건성을 본다. Ablation study는 모델 구조와 학습 구성요소의 변화에 대한 강건성과 기여도를 본다. 하나는 분석 설계의 안정성을 묻고, 다른 하나는 모델 구조의 타당성을 묻는다. 이를 정리하면 다음과 같다.
| 평가 접근 | 핵심 질문 | 주로 바꾸는 것 | 목적 |
|---|---|---|---|
| Sensitivity analysis | 분석 선택을 바꾸어도 결론이 유지되는가? | outcome 정의, cohort 정의, washout, cutoff, 결측 처리, deduplication 방식 | 연구 결론의 강건성 평가 |
| Ablation study | 모델 구성요소가 실제로 성능에 기여하는가? | attention, dropout, class weight, positional encoding, feature set, augmentation | 모델 구조의 타당성 평가 |
| Robustness-oriented evaluation | 이 모델과 결론을 신뢰할 수 있는가? | 데이터, 분석, 모델, 평가 조건 전반 | 성능을 넘어선 신뢰성 검증 |
이 관점에서 좋은 모델 개발 연구는 단순히 “가장 높은 성능”을 보고하는 연구가 아니다. 좋은 연구는 성능이 어떤 조건에서 유지되는지, 어떤 조건에서 약해지는지, 어떤 구성요소가 실제로 필요한지, 어떤 분석 선택에 민감한지를 투명하게 보여준다.
5. 성능 보고에서 신뢰성 검증으로
결국 모델 개발의 목표는 leaderboard에서 가장 높은 숫자를 얻는 것이 아니라, 실제 연구 질문 또는 임상적 의사결정 맥락에서 신뢰할 수 있는 근거를 만드는 것이다. 특히 보건의료 데이터에서는 데이터 생성 과정 자체가 복잡하다. 상병코드는 진단 그 자체라기보다 청구와 진료 맥락의 산물일 수 있고, 약물 처방은 질병의 proxy일 수 있으며, 검사 결과의 availability는 환자군과 의료기관에 따라 달라질 수 있다. 따라서 단일 모델의 성능지표만으로 연구 결론을 정당화하기 어렵다.
딥러닝에서도 마찬가지다. 복잡한 아키텍처가 높은 성능을 냈다고 해서 그 모델이 더 설명력 있거나, 더 안정적이거나, 더 일반화 가능하다는 뜻은 아니다. 모델의 성능은 데이터 분할, 전처리, class imbalance, random seed, threshold, sequence length, feature representation에 따라 달라질 수 있다. 따라서 ablation study와 sensitivity analysis는 선택적 부가 분석이 아니라, 모델의 신뢰성을 설명하기 위한 핵심 분석으로 이해되어야 한다.
모델 개발 연구의 질문은 다음과 같이 확장·이동되어야 한다.
“우리 모델의 AUROC는 얼마인가?” 에서 “우리 모델의 성능은 어떤 조건에서도 유지되는가?” 로.
“우리 모델이 가장 좋은가?” 에서 “우리 모델이 왜 좋은지 설명할 수 있는가?” 로.
“하나의 최종 모델을 제시할 수 있는가?” 에서 “그 모델의 결론을 신뢰할 수 있는 근거를 제시할 수 있는가?” 로.
이것이 성능 중심 모델 개발을 넘어선 강건성 기반 모델 평가의 핵심이다. Sensitivity analysis와 ablation study는 서로 다른 이름을 가진 방법론이지만, 결국 같은 방향을 가리킨다. 모델의 숫자를 보고하는 것을 넘어, 모델의 신뢰성을 검증함으로써 실세계에 영향을 미칠 수 있는 일반화 가능성을 검토하는 것이다.
댓글 남기기